
For the past decade, FastNetMon has been trusted by network operators globally as an elite, ultra-fast out-of-band DDoS detection engine. It acts as the intelligent detection plane, analysing flow telemetry such as NetFlow, sFlow, and IPFIX, spotting anomalies in seconds, and orchestrating upstream mitigation via BGP FlowSpec or RTBH.
But a major evolution is currently brewing in our labs.
We are giving the community a sneak peek at an internal R&D project (currently code-named FastACL). We are building a high-performance inline DDoS filtering stack entirely in-house. FastNetMon is expanding from a world-class detector into a line-rate, software-defined network traffic scrubbing engine.
From DDoS detection to in-line mitigation
FastNetMon is already the best out-of-band DDoS sensor on the market. For thousands of networks globally, the workflow of detecting anomalies by reading network telemetry and mitigating them using BGP FlowSpec or RTBH has been incredibly efficient. This is a proven architectural pattern we’ve built the product on so far.
But we are not stopping there.
There is a distinct need in the market for a fine-tuned, surgical mitigation capability that doesn't rely on edge routers to execute the filtering rules. That is why we are building an inline DDoS mitigation engine completely in-house. We are excited to share the development story so far, with very interesting lab results.

While the product development started much earlier, the project became tangible three months ago when we received a delivery of our specialised server infrastructure. That hardware allowed us to spin up a dedicated VPP lab and finally benchmark our engine against real hardware links.
The engineering objective was simple: put standard x86 commodity hardware directly inside the live data path of a backbone link. Instead of straining a router's finite hardware ACL tables with massive blocklists, every single packet physically flows through our software-defined engine in real time. This allows us to surgically drop malicious traffic on the wire while passing legitimate traffic with minimal latency.
Lab Benchmarks: Testing the Limits of 100G Hardware
To achieve this kind of throughput without relying on proprietary ASIC hardware, our team is building the inline filter on top of VPP (Vector Packet Processing) and DPDK.
Inside our dedicated lab environment – which emulates a 100G backbone using physical DAC and fibre links – we subjected the system to sustained packet-rate stress tests using TRex traffic generation.

The initial results were a massive success. Here is exactly how the data broke down across our two primary testing phases:
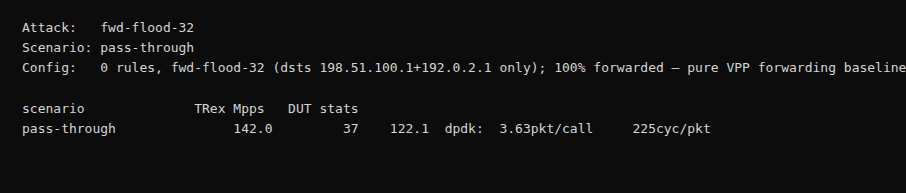
1. Pass-through baseline (no filtering rules)
Before enabling filtering, we established a pass-through baseline with zero rules installed to observe how VPP behaves under sustained high packet rates.
In this configuration, the system sustained approximately 120–126 Mpps depending on measurement layer, with near-full forwarding throughput under load.
Port-level and aggregate measurements show:
- TRex transmit rate: ~142 Mpps
- DUT receive/forwarding range: ~119–122 Mpps
- Aggregate processing rate: ~121.26 Mpps
This provided a reference point for subsequent filtering performance tests under identical hardware conditions.


2. The 1-Million-Rule Stress Test
The true test of an inline filter is how it performs under an enormous firewall rule set during a sustained high-intensity traffic scenario.
We loaded the FastACL stack with 1,000,000 active filtering rules and subjected it to a TRex-generated fwd-flood-32 traffic profile, consisting entirely of minimum-sized 64-byte packets.
Aggregate counters during drop execution:
Packets Bytes pps L3 bps L1 bps
Processed: 1476998528 (1.48 G) 73849926400 (73.85 GB) 140.90 Mpps 56.36 Gbps 99.19 Gbps
Dropped: 1476992993 (1.48 G) 73849649650 (73.85 GB) 140.90 Mpps 56.36 Gbps 99.19 Gbps
The metrics speak for themselves: the working code sustained 140.90 Mpps at 99.19 Gbps, operating at near line-rate for 100G Ethernet with minimum-sized packets, while dropping the traffic and keeping the host system stable under sustained load.
We achieved this by utilising RSS (Receive Side Scaling) to distribute the packet processing workload evenly across 32 physical CPU cores, keeping our per-packet processing budget down to that tiny 225-cycle window.
Lab Environment Specifications
- Device Under Test (DUT): AMD EPYC 7742 (64 cores / 128 threads, single socket), 256 GB DDR4-3200, Mellanox ConnectX-5 100G.
- Traffic Generator (TG): AMD Ryzen 7 5800X, 32 GB DDR4-2133, Mellanox ConnectX-5 100G executing TRex packet generation.
Because our architecture is built on top of the DPDK and VPP ecosystems, we retain low-level control over the data path, enabling fine-grained optimisation of packet processing behaviour as the system evolves.
The 12-Month Roadmap
We are building this technology out in three distinct phases over the next year:
- Stage 1 (Now): Stateless Line-Rate Filtering. The current engine focuses on hyper-fast, stateless packet drops using a FlowSpec-like matching approach (IPs, ports, and basic protocol flags).
- Stage 2 (+3 Months): Deep Payload Bit-Masking. We will introduce flexible filtering that allows operators to match signatures anywhere inside a packet payload using programmable shifts and masks. For example: skip 24 bytes from the beginning of the packet, check if the next two bytes match a specific signature, if not, discard. Operators can stack up to four of these rules per profile for highly complex, per-protocol matching.
- Stage 3 (+12 Months): Stateful TCP Tracking Machine. The engine will evolve to track the state of live connections, allowing it to defend against sophisticated, session-based TCP abuse right at line speed.
Keeping It Open Source
True to FastNetMon’s DNA, this new inline filtering stack will be partially open-source. The core engine is supported by modern, developer-friendly management tools written in Go (Golang), which communicate directly with the VPP backend via a high-speed binary API.
Call for Early Testers
The lab binaries and Go-based management tools will be functional soon.
We want to get this into the hands of our community early. If you are a network operator who has been operating VPP at scale for at least a few years and you want to test-drive this inline filtering technology in your own environment, we want to hear from you. Reach out to our team to join the closed testing group early!



